I originally wrote this post for DataCamp.com. Check out my other work there along with exciting data science courses in R, python, & SQL. This post is part of a series on H1B Data. The other post is here .
I have a friend at a Texas law firm that files H1B visas. The H1B is a non-immigrant visa in the United States of America that allows U.S. employers to employ foreign workers in specialty occupations temporarily. Apparently, getting accepted is extremely difficult because there is a limited visa supply versus thousands of applicants.
Although that is anecdotal, I decided to explore the data myself in the hopes of helping qualified candidates know the US is a welcoming place!
The goal of this tutorial is to show you how you can gather data about H1B visas through web scraping with R. Next, you’ll also learn how you can parse the JSON objects, and how you can store and manipulate the data so that you can do a basic exploratory data analysis (EDA) on the large data set of H1B filings.
Maybe you can learn how to best position yourself as a candidate or some new R code!
Getting Your Data: Web Scraping And Parsing
My DataCamp colleague pointed me to this site which is a simple website containing H1B data from 2012 to 2016. The site claims to have 2M H1B applications organized into a single table.
I decided to programmatically gather this data (read: web scrape) because I was not about to copy/paste for the rest of my life!
As you can see, the picture below shows a portion of the site showing Boston’s H1B data:
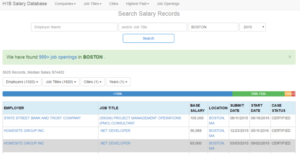
The libraries that this tutorial is going to make use of include jsonlite for parsing JSON objects, rvest which “harvests” HTML, pbapply, which is a personal favorite because it adds progress bars to the base apply functions, and data.table, which improves R’s performance on large data frames.
library(jsonlite) library(rvest) library(pbapply) library(data.table)
Exploring The Page Structure
As you explore the site, you will realize the search form suggests prefill options. For instance, typing “B” into the city field will bring up a modal with suggestions shown below.
The picture below shows the prefill options when I type “B”:

That means that you can use the prefill as an efficient way to query the site.
Using Chrome, you can reload and then right click to “Inspect” the page, then navigate to “Network” in the developer panel and finally type in “B” on the page to load the modal.
Exploring the network panel links, you will find a PHP query returning a JSON object of cities like this.
The goal is first to gather all the suggested cities and then use that list to scrape a wide number of pages with H1B data.
When you explore the previous URL, you will note that it ends in a letter. So, you can use paste0() with the URL base, http://h1bdata.info/cities.php?term=, and letters. The base is recycled for each value in letters. The letters object is a built-in R vector from “a” to “z”. The json.cities object is a vector of URLs, a to z, that contain all prefill suggestions as JSON.
json.cities<- paste0('http://h1bdata.info/cities.php?term=', letters)
Parsing H1B Data JSON Objects
The json.cities object is a vector of 26 links that have to be read by R. Using lapply() or pblapply() along with fromJSON, R will parse each of the JSON objects to create all.cities. You nest the result in unlist so the output is a simple string vector. With this code, you have all prefill cities organized into a vector that you can use to construct the actual webpages containing data.
all.cities<-unlist(pblapply(json.cities,fromJSON))
To decrease the individual page load times, you can decide to pass in two parameters, city and year, into each webpage query. For example, Boston H1B data in 2012, then Boston 2013 and so on.
A great function to use when creating factor combinations is expand.grid().
In the code below, you see that the city information is passed, all.cities, and then year using seq() from 2012 to 2016. The function creates 5000+ city year combinations. expand.grid() programmatically creates a Boston 2012, Boston 2013, Boston 2014, etc. because each city and each year represent a unique factor combination.
city.year<-expand.grid(city=all.cities,yr=seq(2012,2016))
Some cities like Los Angeles are two words which must be encoded for URLs. The url_encode() function changes “Los Angeles” to Los%20Angeles to validate the address. You pass in the entire vector and url_encode() will work row-wise:
city.year$city<-urltools::url_encode(as.character(city.year$city))
Lastly, you use the paste0() function again to concatenate the base URL to the city and state combinations in city.year. Check out an example link here.
all.urls<-paste0('http://h1bdata.info/index.php?em=&job=&city=', city.year[,1],'&year=', city.year[,2])
Extracting Information From Pages
Once you have gone through the previous steps, you can create a custom function called main to collect the data from each page.
It is a simple workflow using functions from rvest.
First, a URL is accepted and read_html() parses the page contents. Next, the page’s single html_table is selected from all other HTML information. The main function converts the x object to a data.table so it can be stored efficiently in memory.
Finally, before closing out main, you can add a Sys.sleep so you won’t be considered a DDOS attack.
main<- function(url.x){
x<-read_html(url.x)
x<-html_table(x)
x<-data.table(x[[1]])
return(x)
Sys.sleep(5)
}
Let’s go get that data!
I like having the progress bar pblapply() so I can keep track of the scraping progress. You simply pass all.urlsand the main function in the pblapply() function. Immediately, R gets to work loading a page, collecting the table and holding a data.table in memory for that page. Each URL is collected in turn and held in memory.
all.h1b<- pblapply(all.urls, main)
Combining The Data Into A Data Table
Phew!
That took hours!
At this point all.h1b is a list of data tables, one per page. To unify the list into a single data table, you can use rbindlist. This is similar to do.call(rbind, all.h1b) but is much faster.
all.h1b<- rbindlist(all.h1b)
Finally save the data so you don’t have to do that again.
write.csv(all.h1b,'h1b_data.csv', row.names=F)
Cleaning Your Data
Even though you scraped the data, some additional steps are needed to get it into a manageable format.
You use lubridate to help organize dates. You also make use of stringr, which provides wrappers for string manipulation.
library(lubridate) library(stringr)
Although this is a personal preference, I like to use scipen=999. It’s not mandatory but it gets rid of scientific notation.
options(scipen=999)
It turns out the web scrape captured 1.8M of the 2M H1B records. In my opinion, 1.8M is good enough. So let’s load the data using fread(): this function is like read.csv but is the more efficient “fast & friendly file finagler”.
h1b.data<- fread('h1b_data.csv')
The scraped data column names are upper case and contain spaces.
Therefore, referencing them by name is a pain so the first thing you want to do is rename them.
Renaming column names needs functions on both sides of the assignment operator (<-). On the left use colnames() and pass in the data frame. On the right-hand side of the operator, you can pass in a vector of strings.
In this example, you first take the original names and make them lowercase using tolower(). In the second line you apply gsub(), a global substitution function.
When gsub() recognizes a pattern, in this case a space, it will replace all instances with the second parameter, the underscore. Lastly, you need to tell gsub() to perform the substitutions in names(h1b.data) representing the now lower case data frame columns.
colnames(h1b.data)<- tolower(names(h1b.data))
colnames(h1b.data)<- gsub(' ', '_', names(h1b.data))
One of the first functions I use when exploring data is the tail() function. This function will return the bottom rows. Here, tail() will return the last 8 rows.
This help you to quickly see what the data shape and vectors look like.
tail(h1b.data, 8)
Now that you have the data set, check out the rest of this post at DataCamp!