This post was originally published at DataCamp. Check out their other curated blog posts.
Picking up at our last post I want to show you how to add more visuals to your Exploratory Data Analysis (EDA) work and introduce some new functions. Last time you learned how to web scrape 1.8m H1B visa applications, correct the variable types, examine some rows and create basic visualizations like barplot and scatterplot.
For this post I will assume you were able to load the data using fread, correct the variables to be dates, change salary to numeric and create new data features like year and month.
First, add some visualizations libraries.
library(ggplot2)
library(ggthemes)Numeric Exploratory Data Analysis: Base Salary
The summary function is a good catch-all when doing EDA work. In this case, you apply the summary() function to a numeric vector $base_salary. In addition to numeric values, you can apply the summary() function to strings and factors to get appropriate descriptive stats. You can even apply it to entire data frames to get column-wise statistics. Here summary() will print the minimum, 1st and third quartile, median, mean and maximum values for H1B salaries.
summary(h1b.data$base_salary)In the summary printout, you should note the maximum value is 7,278,872,788. This definitely seems like a mistake! One way to find the row with the maximum value is with which.max(). The which.max() function determines the row with the first maximum value within the vector it is given, $base_salary.
In the code below, you use this row number to index the data frame so the entire record is printed.
h1b.data[which.max(h1b.data$base_salary)]That is one well paid IBM Software Engineer. Not surprisingly, the H1B case status is “withdrawn”. A quick way to remove an outlier like this is simply to pass in a negative sign along with the which.max statement. Just for educational purposes, you can verify the number of rows in the data frame with nrow before and after the maximum salary is removed.
nrow(h1b.data)
h1b.data<-h1b.data[-which.max(h1b.data$base_salary)]
nrow(h1b.data)Removing a single row is tedious and often is not the best way to remove outliers. Instead, you can plot the salaries to understand the data distribution visually. In this code the innermost function is sort. Sort() accepts the salary vector and by default, sort() will arrange values in ascending order. The next innermost function is the tail() function. In this example, tail() will take the sorted vector and subset it to the last 50 values. Since the order is ascending, tail() will sort the 50 largest salaries. Lastly, base R’s plot function will automatically create a dot plot of the 50 salaries.
plot(tail(sort(h1b.data$base_salary),50))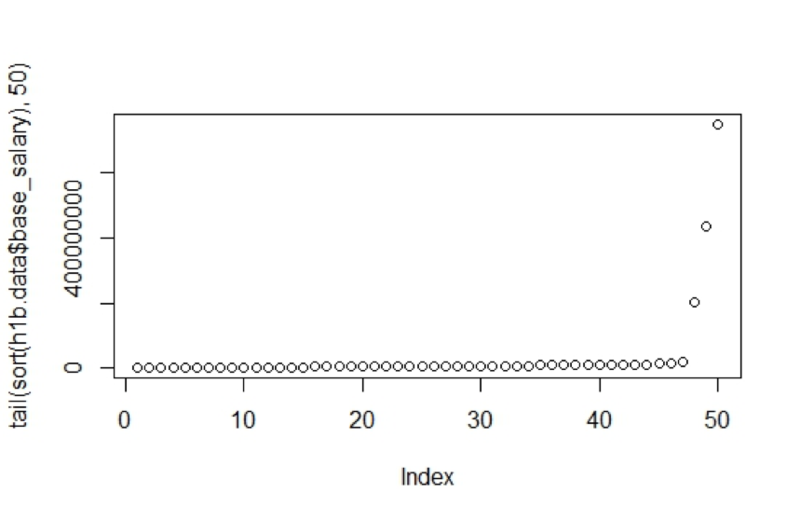
Even with the maximum salary removed, the last 5 salaries range from $10m to $750m.
In this next section, you can learn how to create an arbitrary cutoff using an ifelse statement. This is an efficient way to remove outliers instead of one at a time.
An ifelse statement works like this: if some logical declaration is TRUE then perform an action, otherwise (else) perform another action.
In this code you are rewriting the $basesalary vector using ifelse. Then you call summary() on the vector to display how the ifesle statement changed the output.
Specifically, the code follows this logic: if a $base_salary is greater than $250,000 then change it to NA, otherwise use the original $base_salary.
h1b.data$base_salary<-ifelse(h1b.data$base_salary>250000,NA,h1b.data$base_salary)
summary(h1b.data$base_salary)Notice the summary output now adds 7,137 NA’s to the other descriptive statistics. Furthermore, the maximum value is now 250000.
For continuous data, you can explore the distribution with a kernel density plot. A kernel density plot estimates the population distribution from a sample. Here you are first using ggplot to create a base visual layer.
Start off by passing in the h1b.data and then set the X aesthetic with the column name base_salary. Next, add a geom_density layer to create the kernel density plot. Within the parameters, the code below specifies a fill color, “darkred” and 'NA' for the outline color. In the last layers, you employ ggtheme’s gdocs theme and remove the Y axis text.
ggplot(h1b.data,aes(base_salary)) +
geom_density(fill='darkred', color='NA') +
theme_gdocs() +
theme(axis.text.y=element_blank())You see that the H1B Salaries are mostly above $50K but below $100K.
Categorical EDA: Case Status
Now that you have a basic understanding to explore numeric values you can transition to categorical values.
A categorical value represents a unique class attribute. For example, a day of the week could be Monday, Tuesday, Wednesday, etc. from the 7 daily “levels”. In R, categorical values can mistakenly become strings which means they are all unique even if you are talking about multiple days that are “Tuesday”. In contrast, two categorical Thursdays share the same attribute in that they are both share the “Thursday” level.
In this section, you will review the $case_status vector. H1B visa data repeats in this column leading one to believe they are factors of the application status instead of unique strings. To examine this information, let’s ensure the vector is a factor using as.factor(). This changes the class data to a categorical value. Next, you use table() to tally the information:
h1b.data$case_status<-as.factor(h1b.data$case_status)
table(h1b.data$case_status)Once again, values are not evenly distributed. 1.7m of the 1.8m rows are “CERTIFIED.” Another 95k are “WITHDRAWN” or “DENIED” while the remaining factor levels total less than 20.
The code below demonstrates how to remove the outlier categorical values. First, you create a small vector, drops, containing the factor levels to remove. Each of the factor levels is separated by a pipe “|” operator. The pipe is a straight line above your enter key. In logical expressions, the symbol represents “OR.”
So, the drops object is saying “INVALIDATED OR PENDING QUALITY… OR UNASSIGNED OR REJECTED”.
drops<-c('INVALIDATED|PENDING QUALITY AND COMPLIANCE REVIEW - UNASSIGNED|REJECTED')Next, you use grepl() to declare a TRUE if one of the rows contain a level from drops. The grepl() command is an old UNIX command that searches for a pattern. The output is a TRUE if the pattern is found and FALSE if it is not.
In this case, you are passing in the text from drops as search patterns. In the next parameter, you apply grepl() to the $case_status vector.
Note that the exclamation mark to begin the grepl expression: this symbol represents a negation.
Putting it all together, the negation occurs when grepl returns a TRUE:
h1b.data<-h1b.data[!grepl(drops,h1b.data$case_status),]R retains unused levels even if they are removed. In this case, calling table on the h1b.data$case_status will still show “REJECTED” with a 0. One method to drop unused levels is to call factor on the vector.
You can re-check the tally by using table() again:
table(h1b.data$case_status)
h1b.data$case_status<-factor(h1b.data$case_status)
table(h1b.data$case_status)One way to visualize the new factor distribution is with the data visualization library ggplot.
In the first layer, you pass in the data frame and set aesthetics using aes. This creates the base status.plot for the visual. The next layer adds a geometric bar shape with geom_bar, then flips the x,y axis with coord_flip and finally adds thematic information with theme_gdocs(). The GDocs theme is a shortcut for a predefined color palette. In the last layer, you adjust the GDocs theme by removing the Y Axis title and removing the legend.
status.plot <- ggplot(h1b.data, aes(factor(case_status),fill=factor(case_status)))
status.plot +
geom_bar()+
coord_flip()+
theme_gdocs()+
theme(axis.title.y=element_blank(),legend.position="none")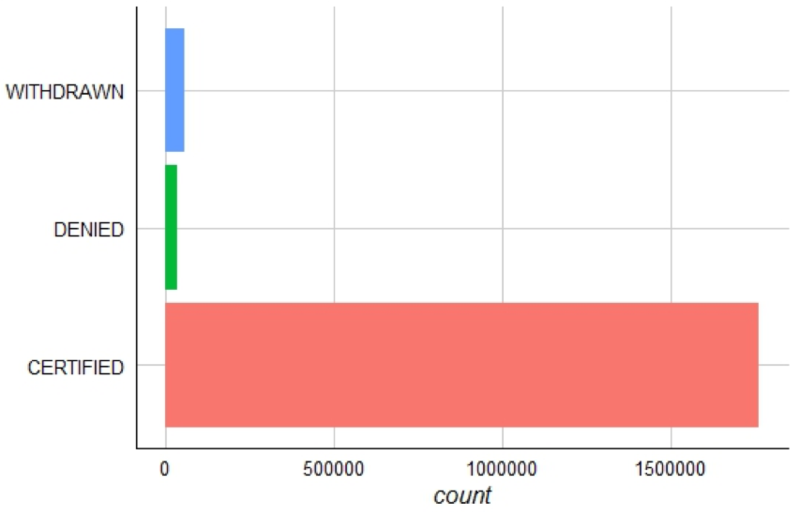
This plot compares the H1B case status factors.
Salary & Status: Numeric by Factor EDA
Another way you can explore data is by looking at the variable interactions. This is particularly helpful if you are doing predictive modeling and can examine inputs by the dependent variable.
In this section, you will explore salary distributions by H1B case status.
In this code, you are building a boxplot. A box plot is a compact way to review population distributions.
The figure below places a normal distribution on the left vertically with a boxplot on the right. In a box plot the population median is represented as a dark line inside the box. The line segments the population into 2nd and 3rd quartiles. The “whiskers” extending outside the box represent the 1st and 4th quartiles. Lastly, the dots are meant to show true outliers to the distribution.

This is a normal distribution alongside a box plot for comparison.
You can construct a boxplot with ggplot and passing in the H1B data. The geom_boxplot() function is the layer that creates the box plot distributions. Within this function, you set the aesthetics of the X axis as case_status with values such as “CERTIFIED”. Within aes, the Y axis is the base_salary and the last parameter simply color codes the different factors.
The next section of code illustrates a third method for outlier removal. Previously, you used which.max() and ifelse to remove outliers.
In a ggplot visual, you can also omit records by limiting the axis.
Here, you are using ylim and passing in 0,100000. This means the Y axis will only extend to $100,000 and ggplot will ignore any others. Lastly, as before, you add theme_gdocs coloring and adjust the theme by removing the X axis text.
ggplot(h1b.data) +
geom_boxplot(aes(factor(case_status), base_salary, fill=as.factor(case_status))) +
ylim(0,100000) +
theme_gdocs() +
scale_fill_gdocs() +
theme(axis.text.x=element_blank())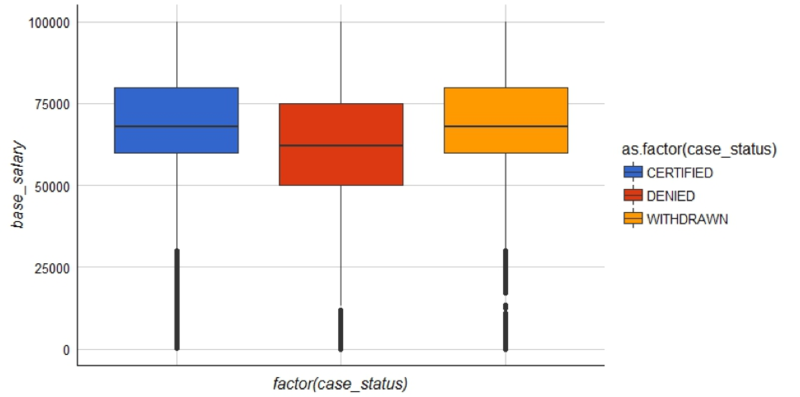
The boxplots show DENIED H1B applications have a lower salary. It also appears that salaries above $75,000 have a better chance of being CERTIFIED.
Temporal EDA: Filing Time
Still another way to explore this data is by time. Assuming you want to know when to apply for your H1B visa you will need to focus on the CERTIFIED applications. Using subset, pass in the entire data frame and then a logical condition.
Any rows where the case_status is equal to “CERTIFIED” will be retained in case.month.
case.month<-subset(h1b.data,h1b.data$case_status=='CERTIFIED')Now you will need to describe the certified applications along two dimensions, month and year.
You will use tapply() to pass in case.month$case$status and then put the other two dimensions into a list. The last parameter is the function to apply over the array. In this case, length will return the number of CERTIFIED H1B applications by year by month. In the second line you call case.month to display the values.
case.month<-tapply(case.month$case_status, list(case.month$submit_month,case.month$submit_yr), length)
case.month| 2012 | 2013 | 2014 | 2015 | 2016 | |
|---|---|---|---|---|---|
| Apr | NA | 29021 | 29687 | 32498 | 32961 |
| Aug | 5 | 22468 | 25903 | 27916 | 31290 |
| Dec | 14635 | 18188 | 22676 | 24990 | NA |
| Feb | NA | 35837 | 52032 | 70787 | 77198 |
| Jan | NA | 22021 | 25268 | 29550 | 30090 |
| Jul | 2 | 23662 | 27396 | 31604 | 26521 |
| Jun | NA | 22356 | 27529 | 33120 | 33565 |
| Mar | NA | 98456 | 112511 | 139680 | 162984 |
| May | NA | 24688 | 27115 | 29131 | 30854 |
| Nov | 16240 | 20727 | 20235 | 19597 | NA |
| Oct | 18493 | 16714 | 24529 | 23156 | NA |
| Sep | 3471 | 20342 | 25913 | 25825 | 20240 |
It is easier to plot this data if you reshape it with data.table’s melt() function. This code will put the month’s years and values into three columns. You can examine the new shape with head().
case.month<-melt(case.month)
head(case.month)Optionally you can change the months to numeric values using the constant month.abb within match(). Here, you rewrite Var1 from month abbreviations to numbers. If you do this, you lose the month labels in the plot but the lines are in temporal order not alphabetical by month name:
case.month$Var1<-match(case.month$Var1,month.abb)
Now that you have the data set, check out the rest of this post at DataCamp!