Abstract: Attendees will learn the foundations of text mining approaches in addition to learn basic text mining scripting functions used in R. The audience will learn what text mining is, then perform primary text mining such as keyword scanning, dendogram and word cloud creation. Later participants will be able to do more sophisticated analysis including polarity, topic modeling and named entity recognition.
Algorithmic Trading in R Tutorial
This post was originally published at DataCamp. Check out their curated blog posts! Unfortunately, loyal3 is no longer with us but check out some of the concepts nonetheless!
In this post, I will show how to use R to collect the stocks listed on loyal3, get historical data from Yahoo and then perform a simple algorithmic trading strategy. Along the way, you will learn some web scraping, a function hitting a finance API and an htmlwidget to make an interactive time series chart.
For this post, a trading algo is defined as a set of rules that trigger a buy or sell event rather than a predictive model or time series forecast. This is the simplest type of trading algo, but if you are interested in digging deeper into finance with R, I would encourage you to take DataCamp’s course in modelling a quantitative trading strategy in R.
Contents
Background
In 2015, I started investing a little at loyal3. Their service is unusual and a great place to start your investment journey. Rather than charge the investor for trades, loyal3 charges the companies to list on their platform. The premise is that people who like a company’s service would also buy the stock and in doing so become strong brand advocates. Making the platform more compelling is that you can buy fractional shares. So, you can get into that $800 amazon stock for only $10 and buy another $10 fraction each time you have a bit of extra cash at the end of the month. Sure there are friction costs since you have to trade in windows and your entire portfolio is limited to ~70 stocks but loyal3 represents a fun and low cost way to explore equity training. You can put real skin in the game for as little as $10!
To be clear, I have the typical retirement and investment accounts but I like loyal3’s clean interface on the app and the lack of fees. I end up checking my fun loyal3 portfolio more often than my mutual funds simply because it is easy and amusing to see the performance of the stocks I directly picked.

Setting Up Your Workspace
To start, load the libraries into your environment. I almost always use rvest for web scraping these days. There are other packages that work including RSelenium, but I like how easy rvest can be executed.
The second package, pbapply, is optional because it simply adds a progress bar to the apply functions. Since you could be scraping hundreds of web pages a progress bar can be helpful to estimate the time.
Next, TTR is a package that I just started to explore. The library is used to construct “Technical Trading Rules”. Although you will learn a simple trading algo in this post, the TTR package can perform more sophisticated calculations and is worth learning.
The dygraphs library is a wrapper for a fast, open source JavaScript charting library. It is one of the htmlwidgets that makes R charting more dynamic and part of an html file instead of a static image. Lastly, the lubridatepackage is used for easy date manipulation.
library(rvest)
library(pbapply)
library(TTR)
library(dygraphs)
library(lubridate)Data Collection
All the loyal3 stocks are all listed on a single page. Before you can look up individual daily stock prices to build your trading algorithm, you need to collect all available stocker tickers. The first thing to do is declare stock.listas a URL string. Next use read_html() so your R session will create an Internet session and collect all the html information on the page as an XML node set. The page CSS has an ID called “.company-name”. Use this as a parameter when calling html_nodes() to select only the XML data associated to this node. Lastly, use html_text()so the actual text values for the company names is collected.
stock.list<-'https://www.loyal3.com/stocks'
stocks<-read_html(stock.list)
stocks.names<-html_nodes(stocks,'.company-name')
stocks.names<-html_text(stocks.names)To examine the stocks that are available on loyal3, you can print the stocks.names object to your console. This returns the company name as a text vector.
stocks.names In order to research the stock prices, you need to get the ticker symbol first. When you are on the loyal3 site, you can click on the company tile to load a page with a ticker symbol and other company information.
Using html_nodes() on stocks, you pull all nodes marked with an “a.” In HTML the <a> tag defines a hyperlink which is used to link form one page to another. Within the hyperlink tag, the “href” refers to the exact URL address. So html_attr() will extract the URL for ALL links on the page if you pass in “href”.
After doing some manual inspection, I found the 54th to 123rd links on the page represent the company pages I need in order to scrape the ticker information. The last line uses paste0() to concatenate the base URL string ’http://www.loyal3.com` to the specific company pages, like “/WALMART”. For example, http://www.loyal3.com/WALMART:
loyal.links<-html_nodes(stocks, "a")
loyal.links<-html_attr(loyal.links, "href")
stock.links<-paste0('http://www.loyal3.com',loyal.links[54:123])On each of the company pages there is a description, a recent closing price and the ticker. All company pages are organized the same so the custom function get.ticker() can be used to extract the ticker symbol.
Within a company’s web page there is a table called “ticker-price”. The function will navigate to a company page, identify the appropriate table, extract the text with html_text(). Lastly, using sub() along with the regular expression ^([[:alpha:]]*).* and \\1 will retain all alphabetical characters. The result is that the any special characters, like $, and any numeric characters, like the closing price, are removed. As the function reads each of the 70 pages, it will only collect the stock ticker.
get.ticker<-function(url){
x<-read_html(url)
x<-html_node(x,'.ticker-price')
x<-html_text(x)
x<-sub("^([[:alpha:]]*).*", "\\1", x)
return(x)
} 
Armed with your custom function, use pblapply() to apply it to each of the stock.links which contain each company’s page. The resulting object, stock.tickers, is a list of individual stock tickers with each element corresponding to an individual company.
stock.tickers<-pblapply(stock.links,get.ticker)One way to change a list of elements into a flat object is with do.call(). Here, you are applying rbind to row bind each list element into a single vector. Lastly, you create a data frame with the symbol and company name information.
stock.ticks<-do.call(rbind,stock.tickers)
stock.ticks<-data.frame(symbol=stock.ticks,name=stocks.names)To be consistent in your analysis, you may want to limit the amount of historical information you gather on each stock. The Sys.Data() function will store a date object as year, month and then day. Using years with an integer is one way to subtract a specific amount of time from the start.date object.
start.date<-Sys.Date()
end.date<-Sys.Date()-years(3)To get the Yahoo finance data, the date object has to be changed to simple character objects without a dash. Using the global substitution function gsub() on both start.date and end.date will change the class and simultaneously remove dashes. Within gsub(), pass in the character pattern to search for, then the replacement characters. In this case the replacing pattern is an empty character in between quotes. The last parameter is the object that gsub() will be applied to.
start.date<-gsub('-','', start.date)
end.date<-gsub('-','', end.date)The TTR() function getYahooData() accepts a stock symbol, and a starting and ending date. The function returns a data frame that has time series information. Each row is a date and the columns contain information such as the “Open”, “High”, “Low” and “Closing” price for an equity. Since you are looking up multiple companies, you can use lapply() or pblapply(). Pass in the vector of company symbols, then the function, getYahooData(), and then the date information. The date objects are recycled parameters each time getYahooData() is applied to a stock symbol.
stocks.ts<-pblapply(stock.ticks$symbol,getYahooData,end.date, start.date)To make selecting the returned list, stocks.ts, easier to navigate you can add names to the list elements. Using names with the stocks.ts object declare the names as the original $symbol vector.
names(stocks.ts)<-stock.ticks$symbolWhen working with large lists, I like to examine the resulting object to make sure the outcome is what I expected. Now that the elements have names, you can reference them directly. In this example, you are examining the first 6 rows for AMC Entertainment Holdings (AMC). Using head() on the list while referencing $AMC will return a portion of the time series for this stock:
head(stocks.ts$AMC)Examining the Stock Data
When I listen to financial news commentators often refer to charts. Despite high frequency trading and active management performed by others, many small investors still refer to charts to gain insight. The time series object can be quickly displayed using plot. Pass in the list referring to the named element such as $AMC and then the column you want to display, here $Close.
plot(stocks.ts$AMZN$Close) The preceding plot is static and not very interesting.
The preceding plot is static and not very interesting.
Let’s use a JavaScript library to make a chart you can explore. In this code snippet, you may observe the “%>%” or pipe operator. The pipe operator is a good way to write concise code. It forwards an object to the next function without forcing you to rewrite an object name like you did earlier in this post.
In this example, you create a dygraph referring to the Twitter stock, $TWTR, and then the column you want to plot, $Close. Within dygraph, main adds a title that is specified in between the quotes. Using the “%>%” this entire object is forwarded to the next function dyRangeSelector(). You can specify a default date range using c()with a start and end date string. The resulting HTML object is a dynamic time series for Twitter’s stock with a date slider at the bottom.
Remember, to change the equity displayed, change the ticker symbol in the stocks.ts list and then the graph title.
dygraph(stocks.ts$TWTR$Close, main = "TWTR Stock Price") %>%
dyRangeSelector(dateWindow = c("2013-12-18", "2016-12-30"))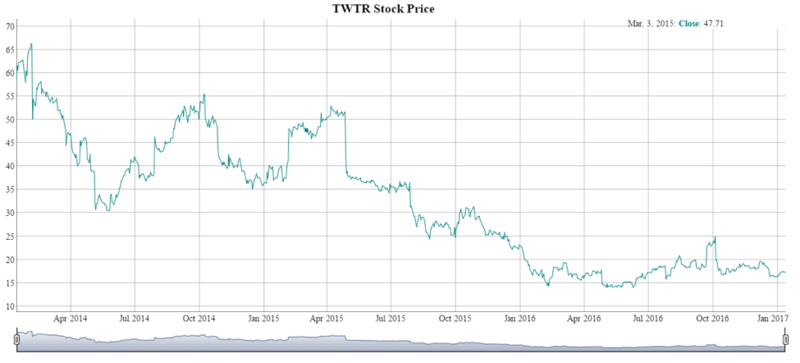
Now that you have the data set, check out the rest of this post at DataCamp!
Posted in blog posts, DataCamp, EDA
Tagged DataCamp, natural language processing, R, text mining
Comments Off on Algorithmic Trading in R Tutorial
Text Mining in R: Are Pokémon GO Mentions Really Driving Up Stock Prices?
This post was originally published at DataCamp. Check out their other curated blog posts.
Introduction: What Bloomberg Terminal’s News Trends Feature (Doesn’t) Show
On a nondescript commute in late July, In the aftermath of the Brexit vote in England and the rise of the hugely popular game called Pokémon GO, I was listening to Bloomberg radio on my way to work. Bloomberg had taken a brief detour from Brexit and the daily musings of the market to instead focus on technology stocks and how to use a Bloomberg Terminal feature called NT (News Trends) to illustrate the information of both news trends and stock prices, aggregating topic mentions across many news sources as a time series. From the description that is all the feature of the $20,000 a month service does. Admittedly I haven’t been in front of a terminal since grad school and I do not remember the NT feature.
The awkward radio broadcast covered a game the “kids” were playing called Pokémon GO and its relationship with Nintendo’s stock. As the conversation wore on detailing how to use NT within a terminal and thereby illustrate the service’s value proposition, Hilary Clark begrudgingly stated that “the stock ticks up for Nintendo were driven… By the mentions of Pokémon GO” and later added, “the value out of this function [NT] is just to see what is driving up the stock price.”
Now, as a text miner, I take particular note of word choice. In communication theory, a message’s meaning lies with the destination not the sender or channel. This means the word choice, tone and medium have an impact on the audience’s comprehension and ascribed attitudes towards the message. You probably already know this inherently, but it is important to note: choosing your words, tone and channel correctly affects the message meaning, anyone who is married knows this firsthand :).
I am guessing you, a DataCamp blog reader, already identified a flaw in Clark’s word choice: as an authority (sender) speaking on an authoritative radio (channel) broadcast, she’s uses words like “driven” (message) in the NT service, which includes a correlation calculation. An unsophisticated consumer of this message may interpret a causal affect from her words and may even attempt to trade stocks using the NT service. However, as the sophisticated audience (destination) that we are, we own the meaning and therefore get to recreate what we think the NT service is and determines its value for ourselves. If it’s so valuable to be part of a $20,000 a month service, then we should be able to gain some novel insight using Google News Trends and Yahoo’s stock service.
Let’s make our own News Trends feature for free and see how awesome a poor man’s Bloomberg Terminal’s NT service could be!
Create Your Own R News Trends Feature
Load the Libraries
To start load the libraries we will need to make the visuals. The quantmod library is a popular R package for importing stock market data. Next, gridExtra and grid are needed to arrange the two resulting visuals. Both ggplot2 and ggthemes are used to construct the time series. ggplot2 is a great grammar of graphics library, while ggthemes provides premade palettes for easy implementation. Lastly, the gtrendsR package provides an interface to get Google Trends data.
It could be that you need to install packages if you don’t have them installed yet. In that case, use for example the install.packages("gtrendsR") command to import the gtrendsR package.
Now that you have the data set, check out the rest of this post at DataCamp!
Posted in blog posts, DataCamp, EDA
Tagged DataCamp, natural language processing, R, text mining
Comments Off on Text Mining in R: Are Pokémon GO Mentions Really Driving Up Stock Prices?
Exploring H-1B Data with R: Part 3
This post was originally published at DataCamp. Check out their other curated blog posts.
We’re back with our third post investigating H-1B data. If you want to learn how to programmatically collect and perform exploratory data analysis (EDA), check out the first post here.
In this final installment, you will learn how to geocode locations for latitude and longitude coordinates from an API. Then you create a map of the data. Next, you learn the top H-1B software developer employers and compare their salaries by year.
I hope these views help you see where you should apply, how much to negotiate for and regions of the country with high volume and good salaries for software developers.
I chose software developers because these are among the most widespread job titles in our data set. Plus, I have a few friends in need of sponsorship that are technically minded. Hopefully this code and the visuals can help them hone their employment efforts!
Get the Data
You could review the original H-1B posts here to web scrape the data like I did. If you do not have the patience, I suggest heading to my github repo to get the CSV file.
The first thing to do is set up your R session with the correct packages. The bit64 packages lets data.tablework efficiently on vectors of 64bit integers.
The data.table package is once again used since it is so efficient. You next use lubridate in case you want to perform data related functions. After that, pbapply gives your R session progress bars when using apply functions. The jsonlite package is used to parse the geocoded API response from Bing Maps. Lastly, plyr is a great package for manipulating data.
The two lines set global options to first get rid of scientific notation and also to increase the decimal places printed to 15. Often you need many decimal points when working with latitude and longitude. Using set.seedensures your visuals will look similar to this post by selecting a specific seed instead of random.
library(bit64)
library(data.table)
library(lubridate)
library(pbapply)
library(jsonlite)
library(plyr)
options(scipen=999, digits=15)
set.seed(1234)The next step is to read in the CSV data from the repository. The fread() function is “fast and friendly file finagler” that quickly reads and provides a progress update. In my experience, it is the best way to import large data frames.
The next lines of code apply ymd to the data related vectors.
If you followed along from the previous posts, you wouldn’t need to do this but using fread() means you will need to correct the vector types.
h1b.data<-fread('h1b_data_clean.csv')
h1b.data$start_date<-ymd(h1b.data$start_date)
h1b.data$submit_date<-ymd(h1b.data$submit_date)Now that your data is in, let’s identify the most frequent job titles. To create h1b.jobs, you should change the $job_title vector to categorical. Next, use table() to tally the unique job titles and nest the result in as.data.frame() so it can be easily manipulated. The third line orders the new data frame by the new $Freqvector. Since the default behavior of order is to arrange values ascending, you can review the 6 most frequent job titles with tail().
h1b.jobs<-as.factor(h1b.data$job_title)
h1b.jobs<-as.data.frame(table(h1b.jobs))
h1b.jobs<-h1b.jobs[order(h1b.jobs$Freq),]
tail(h1b.jobs)Reviewing h1b.jobs, you can pick out the jobs you are interested in.
Here, you can create jobs by concatenating “SOFTWARE DEVELOPER,” “COMPUTER PROGRAMMER” and “SOFTWARE ENGINEER.”
Do you notice how each is separated without a space by the pipe operator? The “|” is above your enter key and represents “OR”. So you are going to subset your h1b.data by “A OR B OR C” e.g. “A|B|C”.
jobs<-c('SOFTWARE DEVELOPER|COMPUTER PROGRAMMER|SOFTWARE ENGINEER')The subset() function will keep a row of data whenever a logical statement is TRUE. Using grepl() to get a logical outcome pass in jobs and search within $job_title. Now h1b.devs has ~262K rows instead of h1b.data’s ~1.8M.
h1b.devs<-subset(h1b.data,grepl(jobs,h1b.data$job_title)==T)Geocoding with Bing Maps
To create a map, you will need lat/lon coordinates. There are multiple services to look up locations like google Maps.
However, I like to use Bing Maps since the limit is 25,000 lookups per day. To use this code sign up here for a Bing Maps API Key. You could look up all locations row by row. However, you would reach your Bing limit quickly and have to wait to finish.
Instead, I suggest looking up each unique location and then joining the information later to save time.
To find unique values in a character vector change the $location with as.factor() and then use levels to extract unique levels.
In this data set, the Software Developer H-1B Applications with 262,659 rows come from only 1,763 unique locations.
all.locs<-levels(as.factor(h1b.devs$location))Some towns like New York have a space that need to be encoded to work properly. The URLencode() function will fill in spaces to make “new%20york.” In this code, URLencode() is applied to the unique location vector, all.locs, and the result is unlisted back to a character vector.
all.locs<-unlist(pblapply(all.locs,URLencode))After signing up, paste your API key in between the quotes to make bing.key. Create the location URLs using paste0(). Pass in the base section of the URL, then the all.locs vector, some more URL information and lastly your API key string. R will recycle all the individual address parts as paste0() works through all.locs.
bing.key<-'BING_MAPS_API_KEY'
bing.urls<-paste0('http://dev.virtualearth.net/REST/v1/Locations?q=',all.locs,'&maxResults=1&key=', bing.key)Next you need a function so you do not have to write code for each URL with location information.
The bing.get() function accepts an individual URL. Using fromJSON the response is collected.
Then, two ifelse statements identify the individual lat/lon values. In each statement if the API provided a response the lat and lon are selected from within the response. If the API couldn’t find the location NA is returned. This helps to overcome API responses without lat/lon values so your code doesn’t break.
Lastly, the lat/lon values are organized into a small data frame.
bing.get<-function(bing.url){
bing.resp<-fromJSON(bing.url, simplifyDataFrame = T)
ifelse(bing.resp$resourceSets$estimatedTotal > 0,
lat<-bing.resp$resourceSets$resources[[1]]$point$coordinates[[1]][1], lat<-'NA')
ifelse(bing.resp$resourceSets$estimatedTotal > 0,
lon<-bing.resp$resourceSets$resources[[1]]$point$coordinates[[1]][2], lon<-'NA')
lat.lon<-data.frame(lat=lat,lon=lon)
return(lat.lon)
}To test the function, apply it to the first bing.urls. If the code works, your R console will print the lat/lon for the first location.
bing.get(bing.urls[1])Now that you verified that the function works and the URLs have been created correctly, you can apply them to the entire bing.urls vector. Using progress bar apply for vectors, pblapply(), pass in the Bing URLs and the bing.get function. This will return a list of 1763 data frames with a $lat and $lon columns.
A fast way to combine the data frames is with rbindlist(), which will bind the list elements row-wise to create a single data frame of lat/lon values.
all.coords<-pblapply(bing.urls,bing.get)
coords.df<-rbindlist(all.coords)In order to join the original Software Developer H-1B visa application data to the location data you need a common value. This code adds $location using the same code to extract unique locations as before. Then $lat and $lon are changed from character to numeric values. The final data frame can be examined with head().
coords.df$location<-levels(as.factor(h1b.devs$location))
coords.df$lat<-as.numeric(as.character(coords.df$lat))
coords.df$lon<-as.numeric(as.character(coords.df$lon))
head(coords.df)Next you need to add the lat/lon values to the h1b.data. Using join will treat the coords.df as a lookup table. Every time one of the locations in h1b.devs is identified in the cords.df data frame the additional $lat and $lon values will be added. To check the number of NA returned from the API use is.na() along with sum().
h1b.devs<- join(h1b.devs,coords.df,by='location')
sum(is.na(h1b.devs$lat))The h1b.devs object contains all H-1B Visa applications for Software Developers along with lat/lon for the job location.
Mapping H-1B Software Developer Information
You can construct a map now that the Software Developer H-1B Data has the appropriate lat and lon. To start, let’s create a static map with unique locations only.
The code below references the 1763 unique lat/lon pairs to demonstrate software developer “hotspots”. For example, San Francisco and San José are distinct locations but using lat/lon you can see how the locations cluster on the map.
For this code add ggplot2 and ggthemes. These are popular grammar of graphics plotting libraries:
library(ggplot2)
library(ggthemes)Start by loading the state map information. Using map_data() with “state” will create a data frame with coordinates and plotting information. This is used as the base layer of the US map.
state.map <- map_data("state")Next create a base ggplot. The polygon layer declares state.map data and X, Y as long/lat respectively. This part of the code is separated so that you can see how the layers are added and changed in the next part.
ggplot() + geom_polygon(data = state.map, aes(x=long,y=lat,group=group),
colour = "grey", fill = NA)
This is the base USA Map layer.
On top of this layer you will add points with geom_point. In this layer you declare the coords.df object with lonand lat. You change the dots to be semi-transparent with alpha and specified color “red”. Next, you limit the plot to center it on the US, add a title, theme and finally remove a lot of elements.
ggplot() +
geom_polygon(data = state.map, aes(x=long,y=lat,group=group),
colour = "grey", fill = NA) +
geom_point(data=coords.df, aes(x=lon, y=lat), alpha=0.05, col="red") +
xlim(-125,-65) + ylim(25,50) +
ggtitle("Certified H1B Visas") +theme_gdocs() +
theme(panel.border = element_blank(),
axis.text = element_blank(),
line = element_blank(),
axis.title = element_blank())The plot is a static image showing clusters of H-1B locations:

Software Developer H-1B Application Locations
It’s better to have a dynamic map so you can interact with the data more freely. The JavaScript leafletpackage has an R package to create HTML-based interactive maps. Load the leaflet library along with htmltools to get started.
library(leaflet)
library(htmltools)Since the plotting of the points is done client side with javascript, it can be time-consuming. As a result, you can sample the data. Sampling a data table can be done while indexing by using sample with .N for number of rows and the sample size, 1000. Next, use jitter() to slightly adjust each lat/lon value in case there are duplicates.
leaf.sample<-h1b.devs[sample(.N,1000),]
leaf.sample$lat<-jitter(leaf.sample$lat)
leaf.sample$lon<-jitter(leaf.sample$lon) An easy way to use leaflet is with the %>% operator.
Confusingly, this is also called the pipe!
This time the pipe operator, %>%, forces an object forward into the next function. This makes code concise and easy to follow.
Here, the leaf.sample data frame is passed into the leaflet() function. The object is forwarded into addTiles()to get map graphics and that again is forwarded into addMarkers(). This could be done with 3 lines of code but only takes one with %>%.
Within the addMarkers() function a popup is added so that you can click on a marker to see the employer.
leaflet(leaf.sample)%>% addTiles() %>% addMarkers(popup = ~htmlEscape(employer))
Now that you have the data set, check out the rest of this post at DataCamp!
Posted in blog posts, DataCamp, EDA
Tagged DataCamp, natural language processing, R, text mining
Comments Off on Exploring H-1B Data with R: Part 3
Exploring H-1B Data with R: Part 2
This post was originally published at DataCamp. Check out their other curated blog posts.
Picking up at our last post I want to show you how to add more visuals to your Exploratory Data Analysis (EDA) work and introduce some new functions. Last time you learned how to web scrape 1.8m H1B visa applications, correct the variable types, examine some rows and create basic visualizations like barplot and scatterplot.
For this post I will assume you were able to load the data using fread, correct the variables to be dates, change salary to numeric and create new data features like year and month.
First, add some visualizations libraries.
library(ggplot2)
library(ggthemes)Numeric Exploratory Data Analysis: Base Salary
The summary function is a good catch-all when doing EDA work. In this case, you apply the summary() function to a numeric vector $base_salary. In addition to numeric values, you can apply the summary() function to strings and factors to get appropriate descriptive stats. You can even apply it to entire data frames to get column-wise statistics. Here summary() will print the minimum, 1st and third quartile, median, mean and maximum values for H1B salaries.
summary(h1b.data$base_salary)In the summary printout, you should note the maximum value is 7,278,872,788. This definitely seems like a mistake! One way to find the row with the maximum value is with which.max(). The which.max() function determines the row with the first maximum value within the vector it is given, $base_salary.
In the code below, you use this row number to index the data frame so the entire record is printed.
h1b.data[which.max(h1b.data$base_salary)]That is one well paid IBM Software Engineer. Not surprisingly, the H1B case status is “withdrawn”. A quick way to remove an outlier like this is simply to pass in a negative sign along with the which.max statement. Just for educational purposes, you can verify the number of rows in the data frame with nrow before and after the maximum salary is removed.
nrow(h1b.data)
h1b.data<-h1b.data[-which.max(h1b.data$base_salary)]
nrow(h1b.data)Removing a single row is tedious and often is not the best way to remove outliers. Instead, you can plot the salaries to understand the data distribution visually. In this code the innermost function is sort. Sort() accepts the salary vector and by default, sort() will arrange values in ascending order. The next innermost function is the tail() function. In this example, tail() will take the sorted vector and subset it to the last 50 values. Since the order is ascending, tail() will sort the 50 largest salaries. Lastly, base R’s plot function will automatically create a dot plot of the 50 salaries.
plot(tail(sort(h1b.data$base_salary),50))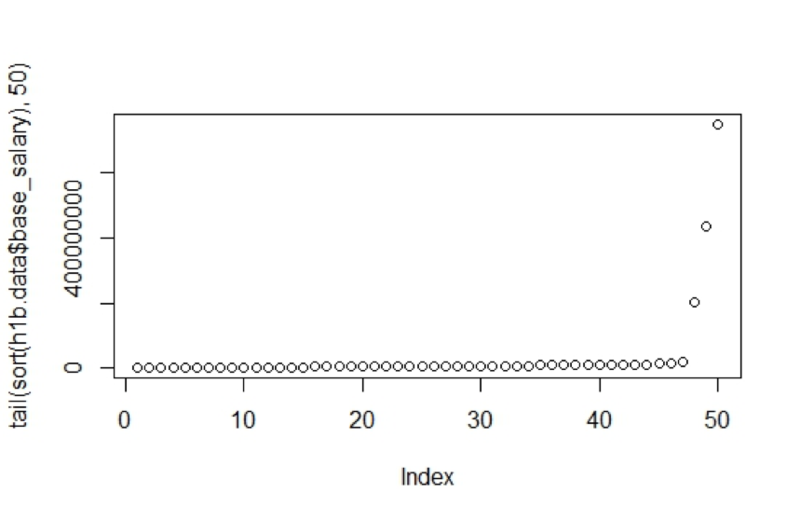
Even with the maximum salary removed, the last 5 salaries range from $10m to $750m.
In this next section, you can learn how to create an arbitrary cutoff using an ifelse statement. This is an efficient way to remove outliers instead of one at a time.
An ifelse statement works like this: if some logical declaration is TRUE then perform an action, otherwise (else) perform another action.
In this code you are rewriting the $basesalary vector using ifelse. Then you call summary() on the vector to display how the ifesle statement changed the output.
Specifically, the code follows this logic: if a $base_salary is greater than $250,000 then change it to NA, otherwise use the original $base_salary.
h1b.data$base_salary<-ifelse(h1b.data$base_salary>250000,NA,h1b.data$base_salary)
summary(h1b.data$base_salary)Notice the summary output now adds 7,137 NA’s to the other descriptive statistics. Furthermore, the maximum value is now 250000.
For continuous data, you can explore the distribution with a kernel density plot. A kernel density plot estimates the population distribution from a sample. Here you are first using ggplot to create a base visual layer.
Start off by passing in the h1b.data and then set the X aesthetic with the column name base_salary. Next, add a geom_density layer to create the kernel density plot. Within the parameters, the code below specifies a fill color, “darkred” and 'NA' for the outline color. In the last layers, you employ ggtheme’s gdocs theme and remove the Y axis text.
ggplot(h1b.data,aes(base_salary)) +
geom_density(fill='darkred', color='NA') +
theme_gdocs() +
theme(axis.text.y=element_blank())You see that the H1B Salaries are mostly above $50K but below $100K.
Categorical EDA: Case Status
Now that you have a basic understanding to explore numeric values you can transition to categorical values.
A categorical value represents a unique class attribute. For example, a day of the week could be Monday, Tuesday, Wednesday, etc. from the 7 daily “levels”. In R, categorical values can mistakenly become strings which means they are all unique even if you are talking about multiple days that are “Tuesday”. In contrast, two categorical Thursdays share the same attribute in that they are both share the “Thursday” level.
In this section, you will review the $case_status vector. H1B visa data repeats in this column leading one to believe they are factors of the application status instead of unique strings. To examine this information, let’s ensure the vector is a factor using as.factor(). This changes the class data to a categorical value. Next, you use table() to tally the information:
h1b.data$case_status<-as.factor(h1b.data$case_status)
table(h1b.data$case_status)Once again, values are not evenly distributed. 1.7m of the 1.8m rows are “CERTIFIED.” Another 95k are “WITHDRAWN” or “DENIED” while the remaining factor levels total less than 20.
The code below demonstrates how to remove the outlier categorical values. First, you create a small vector, drops, containing the factor levels to remove. Each of the factor levels is separated by a pipe “|” operator. The pipe is a straight line above your enter key. In logical expressions, the symbol represents “OR.”
So, the drops object is saying “INVALIDATED OR PENDING QUALITY… OR UNASSIGNED OR REJECTED”.
drops<-c('INVALIDATED|PENDING QUALITY AND COMPLIANCE REVIEW - UNASSIGNED|REJECTED')Next, you use grepl() to declare a TRUE if one of the rows contain a level from drops. The grepl() command is an old UNIX command that searches for a pattern. The output is a TRUE if the pattern is found and FALSE if it is not.
In this case, you are passing in the text from drops as search patterns. In the next parameter, you apply grepl() to the $case_status vector.
Note that the exclamation mark to begin the grepl expression: this symbol represents a negation.
Putting it all together, the negation occurs when grepl returns a TRUE:
h1b.data<-h1b.data[!grepl(drops,h1b.data$case_status),]R retains unused levels even if they are removed. In this case, calling table on the h1b.data$case_status will still show “REJECTED” with a 0. One method to drop unused levels is to call factor on the vector.
You can re-check the tally by using table() again:
table(h1b.data$case_status)
h1b.data$case_status<-factor(h1b.data$case_status)
table(h1b.data$case_status)One way to visualize the new factor distribution is with the data visualization library ggplot.
In the first layer, you pass in the data frame and set aesthetics using aes. This creates the base status.plot for the visual. The next layer adds a geometric bar shape with geom_bar, then flips the x,y axis with coord_flip and finally adds thematic information with theme_gdocs(). The GDocs theme is a shortcut for a predefined color palette. In the last layer, you adjust the GDocs theme by removing the Y Axis title and removing the legend.
status.plot <- ggplot(h1b.data, aes(factor(case_status),fill=factor(case_status)))
status.plot +
geom_bar()+
coord_flip()+
theme_gdocs()+
theme(axis.title.y=element_blank(),legend.position="none")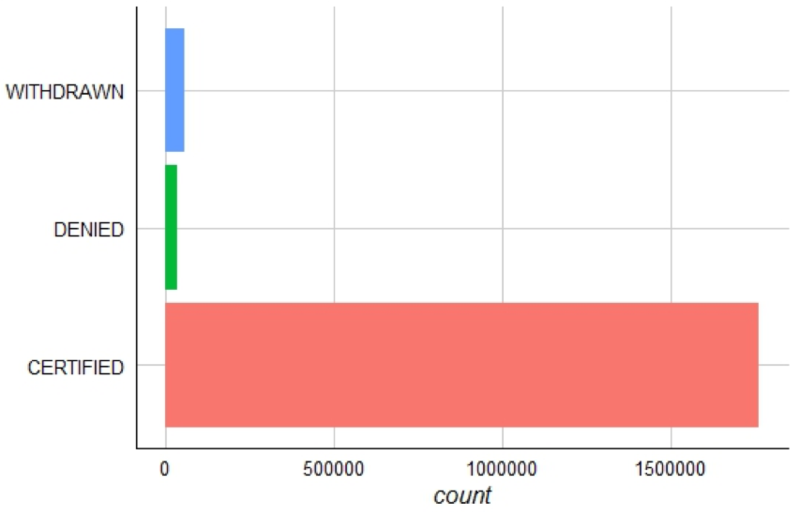
This plot compares the H1B case status factors.
Salary & Status: Numeric by Factor EDA
Another way you can explore data is by looking at the variable interactions. This is particularly helpful if you are doing predictive modeling and can examine inputs by the dependent variable.
In this section, you will explore salary distributions by H1B case status.
In this code, you are building a boxplot. A box plot is a compact way to review population distributions.
The figure below places a normal distribution on the left vertically with a boxplot on the right. In a box plot the population median is represented as a dark line inside the box. The line segments the population into 2nd and 3rd quartiles. The “whiskers” extending outside the box represent the 1st and 4th quartiles. Lastly, the dots are meant to show true outliers to the distribution.

This is a normal distribution alongside a box plot for comparison.
You can construct a boxplot with ggplot and passing in the H1B data. The geom_boxplot() function is the layer that creates the box plot distributions. Within this function, you set the aesthetics of the X axis as case_status with values such as “CERTIFIED”. Within aes, the Y axis is the base_salary and the last parameter simply color codes the different factors.
The next section of code illustrates a third method for outlier removal. Previously, you used which.max() and ifelse to remove outliers.
In a ggplot visual, you can also omit records by limiting the axis.
Here, you are using ylim and passing in 0,100000. This means the Y axis will only extend to $100,000 and ggplot will ignore any others. Lastly, as before, you add theme_gdocs coloring and adjust the theme by removing the X axis text.
ggplot(h1b.data) +
geom_boxplot(aes(factor(case_status), base_salary, fill=as.factor(case_status))) +
ylim(0,100000) +
theme_gdocs() +
scale_fill_gdocs() +
theme(axis.text.x=element_blank())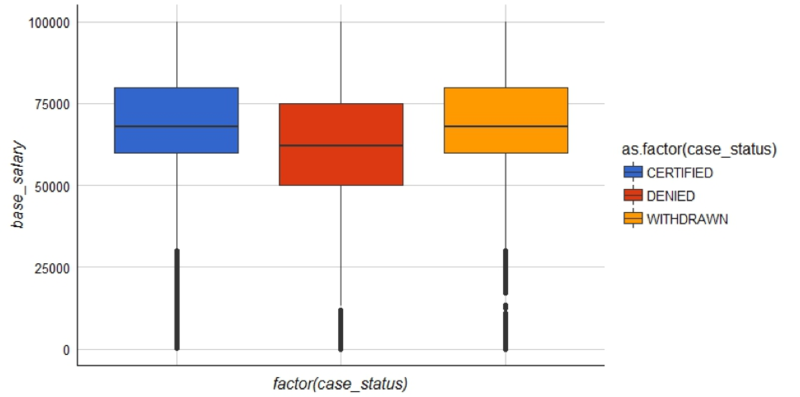
The boxplots show DENIED H1B applications have a lower salary. It also appears that salaries above $75,000 have a better chance of being CERTIFIED.
Temporal EDA: Filing Time
Still another way to explore this data is by time. Assuming you want to know when to apply for your H1B visa you will need to focus on the CERTIFIED applications. Using subset, pass in the entire data frame and then a logical condition.
Any rows where the case_status is equal to “CERTIFIED” will be retained in case.month.
case.month<-subset(h1b.data,h1b.data$case_status=='CERTIFIED')Now you will need to describe the certified applications along two dimensions, month and year.
You will use tapply() to pass in case.month$case$status and then put the other two dimensions into a list. The last parameter is the function to apply over the array. In this case, length will return the number of CERTIFIED H1B applications by year by month. In the second line you call case.month to display the values.
case.month<-tapply(case.month$case_status, list(case.month$submit_month,case.month$submit_yr), length)
case.month| 2012 | 2013 | 2014 | 2015 | 2016 | |
|---|---|---|---|---|---|
| Apr | NA | 29021 | 29687 | 32498 | 32961 |
| Aug | 5 | 22468 | 25903 | 27916 | 31290 |
| Dec | 14635 | 18188 | 22676 | 24990 | NA |
| Feb | NA | 35837 | 52032 | 70787 | 77198 |
| Jan | NA | 22021 | 25268 | 29550 | 30090 |
| Jul | 2 | 23662 | 27396 | 31604 | 26521 |
| Jun | NA | 22356 | 27529 | 33120 | 33565 |
| Mar | NA | 98456 | 112511 | 139680 | 162984 |
| May | NA | 24688 | 27115 | 29131 | 30854 |
| Nov | 16240 | 20727 | 20235 | 19597 | NA |
| Oct | 18493 | 16714 | 24529 | 23156 | NA |
| Sep | 3471 | 20342 | 25913 | 25825 | 20240 |
It is easier to plot this data if you reshape it with data.table’s melt() function. This code will put the month’s years and values into three columns. You can examine the new shape with head().
case.month<-melt(case.month)
head(case.month)Optionally you can change the months to numeric values using the constant month.abb within match(). Here, you rewrite Var1 from month abbreviations to numbers. If you do this, you lose the month labels in the plot but the lines are in temporal order not alphabetical by month name:
case.month$Var1<-match(case.month$Var1,month.abb)
Now that you have the data set, check out the rest of this post at DataCamp!
Posted in blog posts, DataCamp, EDA
Tagged DataCamp, natural language processing, R, text mining
Comments Off on Exploring H-1B Data with R: Part 2
Exploring H1B Data With R: Part 1
I originally wrote this post for DataCamp.com. Check out my other work there along with exciting data science courses in R, python, & SQL. This post is part of a series on H1B Data. The other post is here .
I have a friend at a Texas law firm that files H1B visas. The H1B is a non-immigrant visa in the United States of America that allows U.S. employers to employ foreign workers in specialty occupations temporarily. Apparently, getting accepted is extremely difficult because there is a limited visa supply versus thousands of applicants.
Although that is anecdotal, I decided to explore the data myself in the hopes of helping qualified candidates know the US is a welcoming place!
The goal of this tutorial is to show you how you can gather data about H1B visas through web scraping with R. Next, you’ll also learn how you can parse the JSON objects, and how you can store and manipulate the data so that you can do a basic exploratory data analysis (EDA) on the large data set of H1B filings.
Maybe you can learn how to best position yourself as a candidate or some new R code!
Getting Your Data: Web Scraping And Parsing
My DataCamp colleague pointed me to this site which is a simple website containing H1B data from 2012 to 2016. The site claims to have 2M H1B applications organized into a single table.
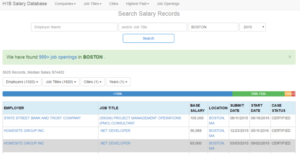
I decided to programmatically gather this data (read: web scrape) because I was not about to copy/paste for the rest of my life!
As you can see, the picture below shows a portion of the site showing Boston’s H1B data:
The libraries that this tutorial is going to make use of include jsonlite for parsing JSON objects, rvest which “harvests” HTML, pbapply, which is a personal favorite because it adds progress bars to the base apply functions, and data.table, which improves R’s performance on large data frames.
library(jsonlite) library(rvest) library(pbapply) library(data.table)
Exploring The Page Structure
As you explore the site, you will realize the search form suggests prefill options. For instance, typing “B” into the city field will bring up a modal with suggestions shown below.
The picture below shows the prefill options when I type “B”:

That means that you can use the prefill as an efficient way to query the site.
Using Chrome, you can reload and then right click to “Inspect” the page, then navigate to “Network” in the developer panel and finally type in “B” on the page to load the modal.
Exploring the network panel links, you will find a PHP query returning a JSON object of cities like this.
The goal is first to gather all the suggested cities and then use that list to scrape a wide number of pages with H1B data.
When you explore the previous URL, you will note that it ends in a letter. So, you can use paste0() with the URL base, http://h1bdata.info/cities.php?term=, and letters. The base is recycled for each value in letters. The letters object is a built-in R vector from “a” to “z”. The json.cities object is a vector of URLs, a to z, that contain all prefill suggestions as JSON.
json.cities<- paste0('http://h1bdata.info/cities.php?term=', letters)
Parsing H1B Data JSON Objects
The json.cities object is a vector of 26 links that have to be read by R. Using lapply() or pblapply() along with fromJSON, R will parse each of the JSON objects to create all.cities. You nest the result in unlist so the output is a simple string vector. With this code, you have all prefill cities organized into a vector that you can use to construct the actual webpages containing data.
all.cities<-unlist(pblapply(json.cities,fromJSON))
To decrease the individual page load times, you can decide to pass in two parameters, city and year, into each webpage query. For example, Boston H1B data in 2012, then Boston 2013 and so on.
A great function to use when creating factor combinations is expand.grid().
In the code below, you see that the city information is passed, all.cities, and then year using seq() from 2012 to 2016. The function creates 5000+ city year combinations. expand.grid() programmatically creates a Boston 2012, Boston 2013, Boston 2014, etc. because each city and each year represent a unique factor combination.
city.year<-expand.grid(city=all.cities,yr=seq(2012,2016))
Some cities like Los Angeles are two words which must be encoded for URLs. The url_encode() function changes “Los Angeles” to Los%20Angeles to validate the address. You pass in the entire vector and url_encode() will work row-wise:
city.year$city<-urltools::url_encode(as.character(city.year$city))
Lastly, you use the paste0() function again to concatenate the base URL to the city and state combinations in city.year. Check out an example link here.
all.urls<-paste0('http://h1bdata.info/index.php?em=&job=&city=', city.year[,1],'&year=', city.year[,2])
Extracting Information From Pages
Once you have gone through the previous steps, you can create a custom function called main to collect the data from each page.
It is a simple workflow using functions from rvest.
First, a URL is accepted and read_html() parses the page contents. Next, the page’s single html_table is selected from all other HTML information. The main function converts the x object to a data.table so it can be stored efficiently in memory.
Finally, before closing out main, you can add a Sys.sleep so you won’t be considered a DDOS attack.
main<- function(url.x){
x<-read_html(url.x)
x<-html_table(x)
x<-data.table(x[[1]])
return(x)
Sys.sleep(5)
}
Let’s go get that data!
I like having the progress bar pblapply() so I can keep track of the scraping progress. You simply pass all.urlsand the main function in the pblapply() function. Immediately, R gets to work loading a page, collecting the table and holding a data.table in memory for that page. Each URL is collected in turn and held in memory.
all.h1b<- pblapply(all.urls, main)
Combining The Data Into A Data Table
Phew!
That took hours!
At this point all.h1b is a list of data tables, one per page. To unify the list into a single data table, you can use rbindlist. This is similar to do.call(rbind, all.h1b) but is much faster.
all.h1b<- rbindlist(all.h1b)
Finally save the data so you don’t have to do that again.
write.csv(all.h1b,'h1b_data.csv', row.names=F)
Cleaning Your Data
Even though you scraped the data, some additional steps are needed to get it into a manageable format.
You use lubridate to help organize dates. You also make use of stringr, which provides wrappers for string manipulation.
library(lubridate) library(stringr)
Although this is a personal preference, I like to use scipen=999. It’s not mandatory but it gets rid of scientific notation.
options(scipen=999)
It turns out the web scrape captured 1.8M of the 2M H1B records. In my opinion, 1.8M is good enough. So let’s load the data using fread(): this function is like read.csv but is the more efficient “fast & friendly file finagler”.
h1b.data<- fread('h1b_data.csv')
The scraped data column names are upper case and contain spaces.
Therefore, referencing them by name is a pain so the first thing you want to do is rename them.
Renaming column names needs functions on both sides of the assignment operator (<-). On the left use colnames() and pass in the data frame. On the right-hand side of the operator, you can pass in a vector of strings.
In this example, you first take the original names and make them lowercase using tolower(). In the second line you apply gsub(), a global substitution function.
When gsub() recognizes a pattern, in this case a space, it will replace all instances with the second parameter, the underscore. Lastly, you need to tell gsub() to perform the substitutions in names(h1b.data) representing the now lower case data frame columns.
colnames(h1b.data)<- tolower(names(h1b.data))
colnames(h1b.data)<- gsub(' ', '_', names(h1b.data))
One of the first functions I use when exploring data is the tail() function. This function will return the bottom rows. Here, tail() will return the last 8 rows.
This help you to quickly see what the data shape and vectors look like.
tail(h1b.data, 8)
Now that you have the data set, check out the rest of this post at DataCamp!
Posted in blog posts, DataCamp, EDA
Tagged DataCamp, natural language processing, R, text mining
Comments Off on Exploring H1B Data With R: Part 1